I refer you to Ben Langhinrichs at Genii Software with his post on “Self deprecating standards”.
After you’ve read that, then I hope you’ll return back here for some additional thoughts.
From what Ben writes, it seems that one source of OOXML’s length and complexity is that it had grandfathered in all sorts of special cases and exceptions for older versions of Office. So an implementor not only must worry about how Office 2007 does footnote placement, but also needs to worry about how Word 6 and Word 95 did it differently. Many other examples in his post. (Ben, you should take a look at the VML section — that entire markup is deprecated in the spec. )
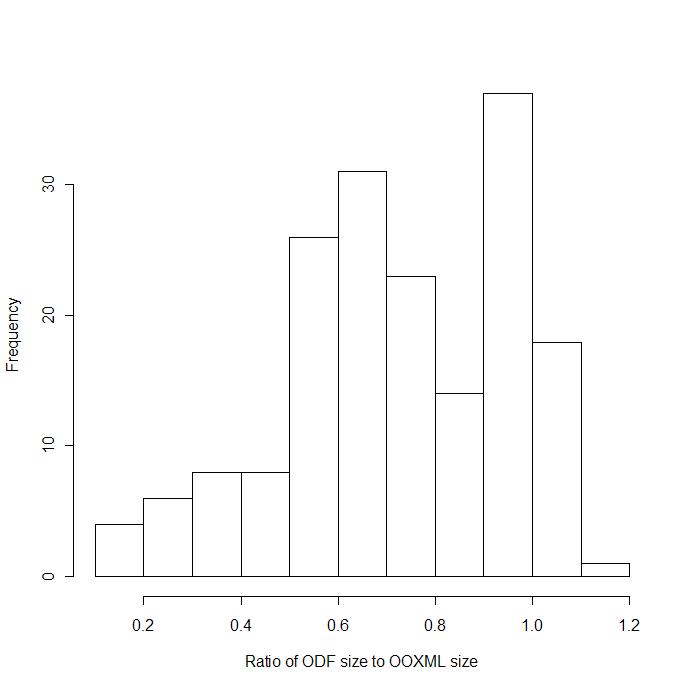
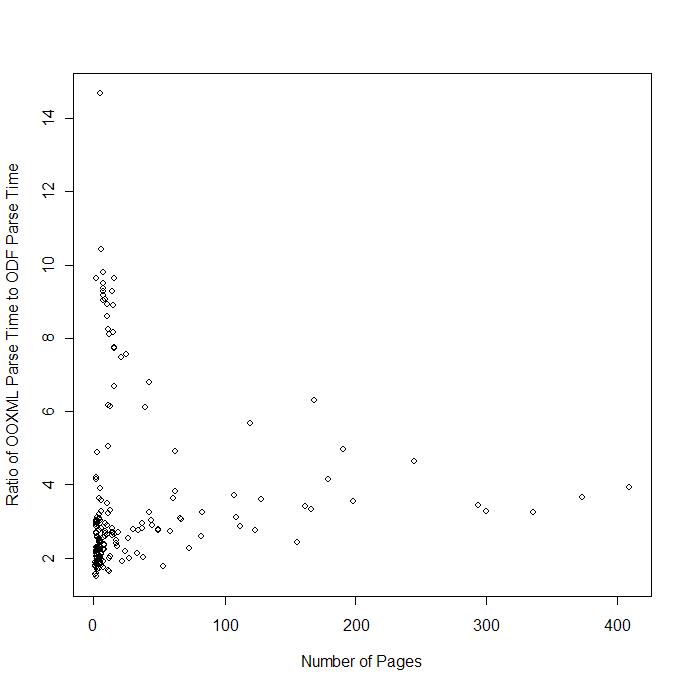
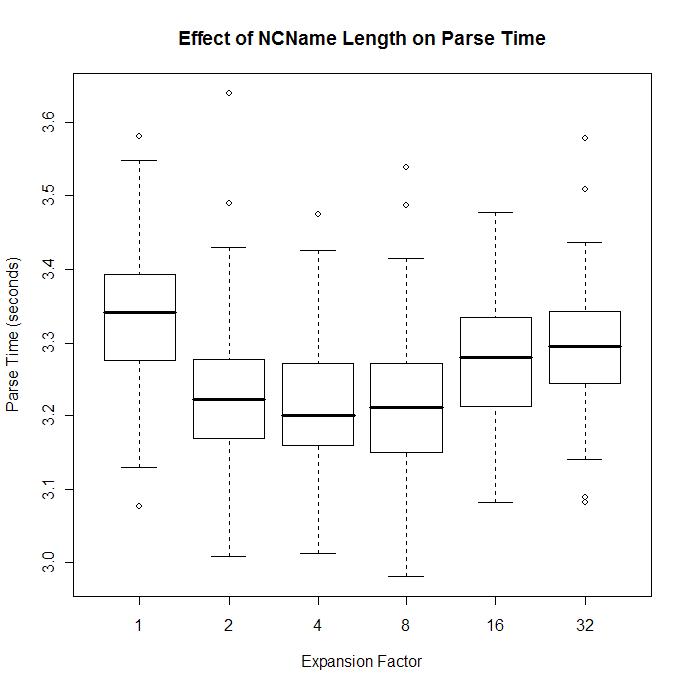
We call this “crud”, the accumulated debris from old implementations, old platforms, old formats, old mistakes. Don’t get me wrong. As a forensic exercise in documenting the byzantine complexity of this arcane format the draft OOXML specification is a considerable achievement. The 6,000 pages testify to the industry of its authors as well as the thanklessness of their task.
But we need to keep in mind that there is a difference between a specification and a standard. A specification tells the plain facts of what a particular technology does without comment as to whether it is good or bad. I could drop a box of toothpicks on my desk and write up a detailed specification on how they landed. An open standard, on the other hand, goes beyond mere specification, and promotes a preferred way of achieving cross-vendor and cross-application interoperability. Ideally a standard says, “This specification is good, we thought of the wider needs of the market, including other vendors and the consumer, and if we all implement this technically elegant specification then we all win.”
However one thinks of the OOXML specification, it lacks the quality, the consideration and the perspective of an open standard. It was doomed from day 1, when its charter limited TC45 to not making any changes that would be incompatible with Microsoft’s existing proprietary binary formats. Think of it this way — The binary formats were certainly never designed to be a standard, right? They were developed in-house at Microsoft, kept from public scrutiny for 15 years, never brought before a standards organization, licensed on terms that prevented competition with Office, etc. Now, 15 years later they take the accumulated crud from 15 years of a proprietary binary format, convert it into XML and expect to call that an “open standard”?
From an architectural and design perspective this is all ass-backwards. You can build complexity on top of simplicity, but you can’t easily build simplicity on top of complexity. The recommended approach when designing a standard-aspiring document format is to survey the range of functionality in existing and anticipated implementations, map out the intersection of this complexity and then generalize it. The generalization of complexity often leads to simplification. A good example is the art page borders, where the OOXML specification enumerates hundreds of specific images that can be used in page borders, an approach which is at once limiting and complex. The generalization of having the document include the clipart would both simplify the specification as well as increase its functionality. Instead of this approach, Microsoft has squandered their opportunity to improve document-centric computing and interoperability and instead produced 6,000 pages of indigestible complexity, an approach that cuts off alternate implementations and props up their monopoly.
It is time to move on.