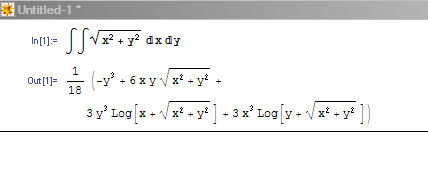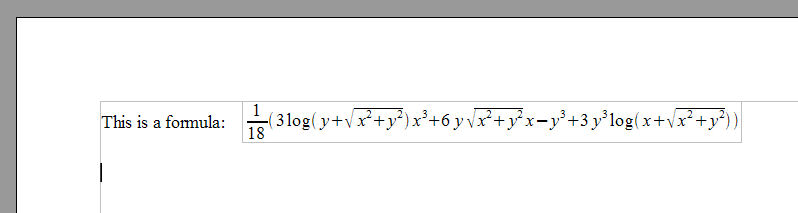As he stood staring at them, they asked him no questions, for his face told them everything.
‘I cannot find it,’ said he, ‘and I must have it. Where is it?’
His head and throat were bare, and, as he spoke with a helpless look straying all around, he took his coat off, and let it drop on the floor.
‘Where is my bench? I’ve been looking everywhere for my bench, and I can’t find it. What have they done with my work? Time presses: I must finish those shoes.’
They looked at one another, and their hearts died within them.
Charles Dickens, a careful student of human nature, provides us here a vivid portrait of Dr. Alexandre Manette, who, after being held 18 years in the Bastille, is released, but is unable to adjust to his new freedom, and in times of stress lapses back to the familiarity of his prison labors, making shoes.
We all have been prisoners of Microsoft Office and their proprietary file formats. You may no longer recognize it as a prison, because this cell has been your home for the past 15 years, but here is what it looks like:
- Editing a document requires Microsoft Office.
- Since Office runs only on Windows, you also require Windows
- These restrictions lead to a purely heavy-client view of document processing.
- This also leads to a model of programmability that emphasizes storing executable code (macros/script) inside of the document, resulting in years of security nightmares. Here is a typical recital of the known dangers.
- If you don’t want to put script inside your document, you could access the data via Office automation API’s, but this again required a machine running Windows and Office.
- It also emphasizes a view of WYSIWYG which emphasizes early formatting and layout decisions and de-emphasized semantic richness in documents. For example, see “What has WYSIWYG Done to Us?”.
- The tools that were created for us to record our thoughts instead now constrain or even substitute for our thoughts. For example, “PowerPoint Panders to our Weaker Points” in the Guardian, and Tufte’s “PowerPoint is Evil”.
- The above also lead to a stifled the market for 3rd party document processing tools. We will never see the value of what was never allowed to occur, but the opportunity cost of the innovation that did not happen in this single-vendor world is enormous.
- This also lead to general lack of competition in the productivity editor market, leading to a decade of buggy products with little innovation. Is the “Ribbon” the most we can look forward to?
- We’ve been locked into a one-size-fits-all offerings of bloated applications. Many people are over-served by Office and therefor are over-paying for functionality they do not need, while others are under-served by the resulting products they cannot afford.
- Functionality has been arbitrarily segregated into three and only three application classes, “Spreadsheet”, “Word Processor” and “Presentation Graphics”.
The move from proprietary binary formats to new standard formats, like OpenDocument Format (ODF), is a movement from imprisonment to freedom. The technical constraints have been lifted, but have we really made the mental adjustments necessary to engage our new freedom? Or are we still silently pacing a 10-foot cell in our minds? If we merely recreate our cell walls in XML, then we are still prisoners.
I am a creature of habit and have been as much a prisoner as you have, so don’t look to me for all the answers. But I do have a few thoughts on what this new freedom might look like.
Instead of being opaque black boxes that can only be used on one vendor’s system, documents will be transparent. Anyone can access them using whatever operating system and whatever tools they want, and for any purpose they want. Python on Linux, REXX on AS/400, and C# on Windows will all have equal opportunity.
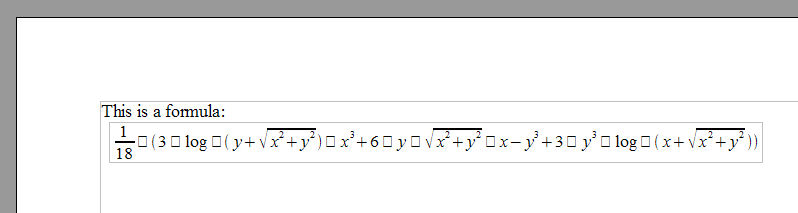
This also implies that document processing will no longer be restricted, technically or by license, to the desktop. Innovative things will occur on servers. We’re starting to see some of that with Google Docs and wikiCalc. But that is only the beginning. We will see search engines that can intelligently search content for specific MathML expressions, spiders that will collect and aggregate slides from presentations and allow you to share them, document repositories that will automatically check citations in papers and calculate the intellectual social networks these imply, stock brokers that will allow you to download your statements formatted in a spreadsheet, with additional analytics calculated via spreadsheet formulas. Creating, editing, reading, viewing, storing, collaborating will be able to be done anywhere, from your cellphone to the largest servers.
Since the server typically has access not only to your own documents, but your organization’s as well, as well as easy access to other information about the users, such as your role and group via LDAP, an application can drive workflows that relate the contents of the document to similar content, as well as to you organizational role, and to your business. The companies that unlock the knowledge stored by your knowledge workers in your organization’s documents will be the companies leading us into the next decade.
The old walls will fall that once segregated functionality into the arbitrarily defined boundaries of “Spreadsheet”, “Word processor”, and “Presentation graphics”. Dan Bricklin is leading the way with his wikiCalc. Is it a Spreadsheet or is it a Wiki? If you have to ask the question then you are still a prisoner. The point is wikiCalc is whatever Dan Bricklin wants it to be. That is freedom to innovate. We will see the arbitrary divisions between application genres become fuzzy and fall away as we all recognize our new freedom.
Document programmability will be turned inside-out. Instead of putting code inside of the document, turning documents into virus vectors, the code will be carefully segregated. Once the code and the data are distinct, we can put the code on the server, where it can be more easily managed, maintained, and secured. This clean separation of code and data will be as important to system stability and security as was protected-mode in the 80286 processor when it first enforced this data/code separation at operating system level. I see macro viruses becoming a thing of the past, like smallpox, because the importance of data/code separation will finally be enforced, and users will not be emailing around code disguised in documents.
We will start thinking of documents as data, and as inputs to modules that process data. I see visual design tools that will allow you to drag and drop a document template onto a design surface and expose various fields in the document which can be wired up to databases, web services or other data sources.
I see financial analysts creating financial models in spreadsheets, then converting the spreadsheet into a web application that can then be deployed anywhere to provide browser-based access and execution of the model via any browser.
I see a variety of productivity editors available at a variety of price points, from free, open source ones, to commercial offerings for desktop and other devices, to specialized offerings with extra features for vertical markets, like legal, medical, academic, or scientific uses.
I see an escape from documents-as-pictures, where users sweat over pixel-perfection and pray that the applications don’t screw them up. Today the end user doesn’t worry about font kerning. We rely on the font managers to get this right, and we accept the results, and concentrate on what we, the authors, add to the document. We are freed from that mental burden of kerning. But why stop there? With smarter applications, we will be freed of most or all formatting burdens. We will concentrate on writing, not on styling, and rely on the applications to get the appearance right. This will free our time to give an increased emphasis on semantic richness, putting our knowledge and experience and outlooks and opinions into the document, and encoding it in an way that allows new modes of collaboration and redefines what a document is.
That is a gimpse at what freedom looks like to me. But let’s not forget that being freed is not the same as being free. There are those out there who are attempting to merely recreate the same single-vendor closed system we’ve had for the past 10 years, and recoding it in XML. This may be a comfortable choice to those who have known no other way. But is it really freedom? I look out and see the jailer offering to sell 10-foot apartments to those just released from their 10-foot prison cells. Will you follow?
Change Log
1/30/2007 — updated wikiCalc link, made other assorted wording changes at my whim, corrected a spelling error, changed to curly quotes.