Of course, one could simply dismiss this question, saying that a specification for an XML vocabulary does not have performance as such, since a specification cannot be executed. However, the choices one makes in designing an XML language will impact the performance of the applications that work with the format. For example, both ODF and OOXML store their XML in compressed Zip files. This will cause reading and writing of a document to be faster in cases where memory is plentiful and computation is much faster than storage and retrieval, which is to say on most modern desktops. But this same scheme may be slower in other environments, say PDA’s. In the end, the performance characteristics of a format cannot be divorced from operational profile and environmental assumptions.
When comparing formats, it is important to isolate the effects of the format versus the application. This is important from the analysis standpoint, but also for legal reasons. Remember that the only implementation of (draft) OOXML is (beta) Office 2007, and the End User Licence Agreement (EULA) has this language:
7. SCOPE OF LICENSE. …You may not disclose the results of any benchmark tests of the software to any third party without Microsoft’s prior written approval
So let’s see what I can do while playing within those bounds. I started with a sample of 176 documents, randomly selected from the Ecma TC45’s document library. I’m hoping therefore that Microsoft will be less likely to argue that these are not typical. These documents are all in the legacy binary DOC format and include agendas, meeting minutes, drafts of various portions of the specification, etc.
Some basic statistics on this set of documents:
Min length = 1 page
Mode = 2 pages
Median length = 7 pages
Mean length = 34 pages
Max length = 409 pages
Min file size= 27,140 bytes
Median file size= 159,000 bytes
Mean file size= 749,000 bytes
Max file size= 15,870,000 bytes
So rather than pick a single document and claim that it reflects the whole, I looked at a wide range of document sizes in use within a specific document-centric organization.
I converted each document into ODF format as well as OOXML, using OpenOffice 2.03 and Office 2007 beta 2 respectively. As has been noted before, both ODF and OOXML formats are XML inside of a Zip archive. The compression from the zipping not only counters the expansion factor of the XML, but in fact results in files which are smaller than the original DOC files. The average OOXML document was 50% the size of the original DOC file, and the average ODF document was 38% the size of the DOC. So net result is that the ODF documents came out smaller, averaging 72% of their OOXML equivalents.
A quick sanity check of this result is easy to perform. Create an empty file in Word in OOXML format, and an empty file in OpenOffice in ODF format. Save both. The OOXML file ends up being 10,001 bytes, while the ODF file is only 6,888 bytes, or 69% of the OOXML file.
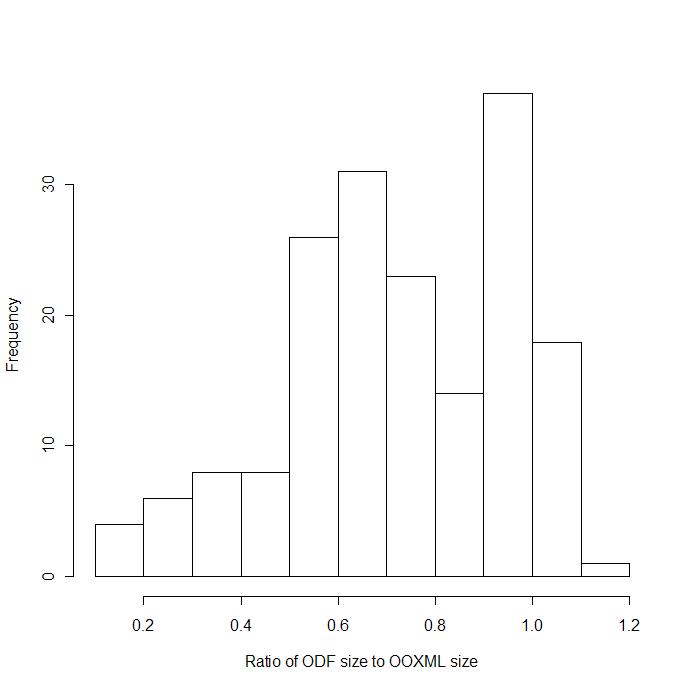
Here is a histogram of the ODF/OOXML size ratios for the sampled files. As you can see, there is a wide range of behaviors here, with some files even ending up larger in ODF format. But on average the ODF files were smaller.
What about the contents of the Zip archives? The OOXML documents tended to contain more XML files (on average 6 more) than the parallel ODF document, but these XML files were individually smaller, average 32,080 bytes versus 66,490 for ODF. However the net effect is that the average total size of the XML in the OOXML is greater than in ODF (684,856 bytes versus 401,406 bytes).
Here’s part 2 of the experiment. The proposal is that many (perhaps most) tools that deal with these formats will need to read and parse all of the XML files within the archive. So a core part of performance that these apps will share is how long it takes to unzip and parse these XML files. Of course this is only part of the performance story. What the application does with the parsed data is also critical, but that is application-dependent and hard to generalize. But the basic overhead of parsing is universal.
To test this out wrote a Python script to time how long it takes to unzip and parse (Python 2.4 minidom) all the XML’s in these 176 documents. I repeated each measurement 10 times and averaged. And I did this for both the OOXML and the ODF variants.
The results indicate that the ODF documents were parsed, on average 3.6x faster than the equivalent OOXML files. Here is a plot showing the ratio of OOXML parse time to ODF parse time as a function of page size: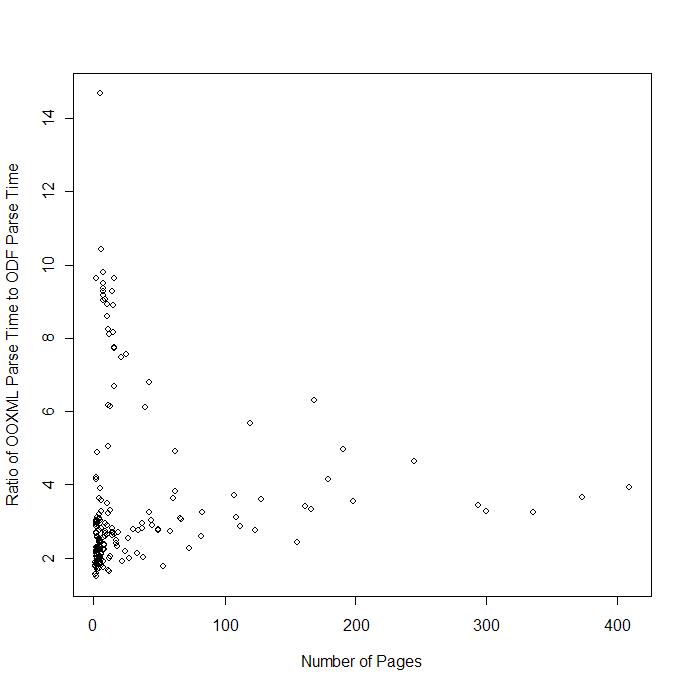 As you can see there is a wide variation in this ratio, especially with shorter documents. In some case the OOXML document took 8x or more longer time to parse than the equivelant ODF document. But with longer documents the variation settles out and settles on the 3.6x factor mentioned
As you can see there is a wide variation in this ratio, especially with shorter documents. In some case the OOXML document took 8x or more longer time to parse than the equivelant ODF document. But with longer documents the variation settles out and settles on the 3.6x factor mentioned
Now how do we explain this? A rough model of XML parsing performance is that it has a fixed overhead to start up, initialize data structures, parse tables, etc., and then some incremental cost dependent on the size and complexity of the XML document. Most systems in the world work like this, fixed overhead plus incremental cost per unit of work. This is true whether we’re talking about XML parsing, HTTP transfers, cutting the lawn or giving blood at a blood bank. The general insight into these systems is that where the fixed overhead is significant, you want to batch up your work. Doing many small transactions will kill performance.
So one theory is that OOXML is slower because of the cost of initializing more XML parses. But it could also be because the aggregate size of the XML files are larger. More testing would be required to gauge the relative contribution of these two factors. However one thing is clear. Although this test was done with minidom on Python, the results are of wide applicability. I can think of no platform and no XML parser for which a larger document comprised of more XML files would be faster than a smaller document made up of fewer XML files. Parsing ODF word processing documents should be faster than OOXML versions everywhere.
I’m not the first one to notice some of these difference. Rick Jelliffe did some analysis of the differences between OOXML and ODF back in August. He approached it from a code complexity view, but in passing noted that the same word processor document loaded faster in ODF format in OpenOffice compared to the same document in OOXML format in Office 2007 beta. On the complexity side he noted that the ODF markup was more complex than the parallel OOXML document. So if ODF is more complex but also smaller, this may amount to higher information density, compactness of expression, etc., and that could certainly be a factor in performance.
So what’s your theory? Why do you think ODF word processing documents are faster than OOXML’s?
I would really, really not want you on the opposite team in a debate (and, yes, that is a compliment).
Thanks. I wouldn’t want to be on the other side of this argument either ;-)
Another weird test.
How can you test with .doc files that are converted to ODF.
I told Jeff Reliife as well that that isn’t a good start of his test. You cannot be sure that what you are testing is actually the same thing. The converted files in ODF might be a lot more basic than the OOXML files.
For those that really want to test they will have to create some files and not convert them from some another format !!!
Converting to another format often leads to simpler files with less functionality.
This is even already the case if you convert ODF files to ODF files using another application.
Very poor rating for this test. But keep going you guys at IBM. It looks you got quite a few people on it at moment.
hAl,
I’ve certainly checked these documents to ensure that the conversions were successful. There is no evident data loss. The source documents were simple, generally plain text with little styling, some embedded graphics, but nothing complicated. OpenOffice does a great job at converting documents like these.
Of course, I say there are no “evident” differences. Who knows what differences there are that are not visible? Of course, that is true even if I took your approach of creating the documents from scratch in both word processors. How do I know that both are saving the same amount of information?
For example, whether I want it or not, Office 2007 tracks revision ID’s for every block of text I enter into a document. This is in the rsidR attribute in document.xml, also referenced in settings.xml. This is tracked even though I do not have “Track Changes” enabled in Word. This can take up a considerable amount of space. OpenOffice does not do anything like this. So even if I created documents from scratch in both word processors, OOXML would come out at a disadvantage because of that.
Another approach would be to hand-craft these XML files in an XML editor based purely on the specifications. This would be very time consuming, and even then I could still be accused on not taking advantage of the optimal encoding of the document allowed by each document.
However, as Microsoft has said on numerous occasions, the legacy support of the “billions” of outstanding Office documents is great importance. I believe this test accurately reflects the performance characteristics that these legacy documents will see when converted to OpenOffice or Office 2007. This is a real-world use and should be a real-world concern.
Any chance you can post plots of those charts with the ratios reversed? (This verifies that the ratio isn’t biasing the plotting). The real problem with OOXML is that MS XML experts applied a new paradigm to the old way of doing things. The new XML paradigm should be coupled with a review of the way the customer does things and how he could improve the way things are done. MS Office has been the business office software standard for quite some time now and MS thinks it knows more about its customers needs than its customers do. MS needed to team with its customers not develop OOXML in an ivory tower in Redmond.