I’ve been hearing some rumblings from the north-west that Ecma Office Open XML (OOXML) format has better performance characteristics than OpenDocument Format (ODF), specifically because OOXML uses shorter tag names. Putting aside for the moment the question of whether OOXML is in fact faster than ODF (something I happen not to believe), let’s take a look at this reasonable question: What effect does using longer, humanly readable tags have on performance compared to using more cryptic terse names?
Obviously there are a number of variables at play here:
- What XML API are you using? DOM or SAX? The overhead of holding the entire document in memory at once would presumably cause DOM to suffer more from tag length than SAX.
- What XML parser implementation are you using? The use of internal symbol tables might make tag length less important or even irrelevant in some parsers.
- What language are you programming in? Some language, like Java have string internalization features which can conflate all identical strings into a single instance.
- What size document are you working with? Document parsing has fixed overhead as well as overhead proportionate to document size. A very short document will be dominated by fixed costs.
So there may not be a single answer for all users with all tools in all situations.
First, let’s talk a little about the tag length issue. It is important to note that the designer of an XML language has control over some, but not all names. For example take a namespace declaration:
xmlns:ve="http://schemas.openxmlformats.org/markup-compatibility/2006"
The values of namespace URI’s are typically predetermined and are often long in order to reduce the chance of accidental collisions. But the namespace prefix is usually chosen to be quite short, and is under the control of the application writing the XML, though a specific prefix is typically not mandated by language designer.
Element and attribute names can certainly be set by the language designer.
Attribute values may or may not be determined by the language designer. For example:
val="Heading1"
Here the name of the style may be determined by the template, or even directly by the user if he is entering a new named style. So the language designer and the application may have no control over the length of attribute values. Other attribute values may be fixed as part of the schema, and the length of those are controlled by the language designer.
Similarly, the length of character content is also typically determined by the user, since this is typically how free-form user content is entered, i.e., the text of the document.
Finally, note that the core XML markup for beginning and ending elements, delimiting attribute values, character entities etc., are all non-negotiable. You can’t eliminate them to save space.
Now for a little experiment. For the sake of this investigation, I decided to explore the performance of a DOM parse in Python 2.4 of a medium-sized document. The document I picked was a random, 60 page document selected from Ecma TC45’s XML document library which I converted from Microsoft’s binary DOC format into OOXML.
As many of you know, an OOXML document is actually multiple XML documents stored inside a Zip archive file. The main content is in a file called “document.xml” so I restricted my examination to that file.
So, how much overhead is there in a our typical OOXML document? I wrote a little Python script to count up the size of all of the element names and attributes names that appeared in the document. I counted only the characters which were controllable by the language designer. So w:pPr counts as three characters, counting only “pPr” since the namespace and XML delimiters cannot be removed. “pPr” is what the XML specification calls an NCName, also called a non-qualified name, since it is not qualified or limited by a namespace. There were 51,800 NCName’s in this document, accounting for 16% of the overall document size. The average NCName was 3.2 characters long.
For comparison, a comparably sized ODF document had an average NCName length of 7.7 and an NCName’s represented 24% of the document size.
So, ODF certainly uses longer names than OOXML. Personally I think this is a good thing, from the perspective of readability, a concern of particular interest to the application developer. Machines will get faster, memory will get cheaper, bandwidth will increase and latency will decrease, but programmers will never get any smarter and schedules will never allow enough time to complete the project. Human Evolution progresses at too slow a speed. So if you need to make a small trade-off between readability and performance, I usually favor readability. I can always tune the code to make it faster. But the developers are at a permanent disadvantage if the language uses cryptic. I can’t tune them.
But let’s see if there is really a trade-off to be made here at all. Let’s measure, not assume. Do longer names really hurt performance as Microsoft claims?
Here’s what I did. I took the original document.xml and expanded the NCNames for the most commonly-used tags. Simple search and replace. First I doubled them in length. Then quadrupled. Then 8x longer. Then 16x and even 32x longer. I then timed 1,000 parses of these XML files, choosing the files at random to avoid any bias over time caused by memory fragmentation or whatever. The results are as follows:
| Expansion Factor | NCName Count | Total NCName Size (bytes) | File size (bytes) | NCName Overhead | Average NCName Length (bytes) | Average Parse Time (seconds) |
|---|---|---|---|---|---|---|
| 1 (original) | 51,800 | 166,898 | 1,036,393 | 16% | 3.2 | 3.3 |
| 2 | 51,800 | 187,244 | 1,056,739 | 18% | 3.6 | 3.2 |
| 4 | 51,800 | 227,936 | 1,097,443 | 21% | 4.4 | 3.2 |
| 8 | 51,800 | 309,320 | 1,178,827 | 26% | 6.0 | 3.2 |
| 16 | 51,800 | 472,088 | 1,341,595 | 35% | 9.1 | 3.3 |
| 32 | 51,800 | 797,624 | 1,667,131 | 48% | 15.4 | 3.3 |
If you like box-and-whisker plots (I sure do!) then here you go: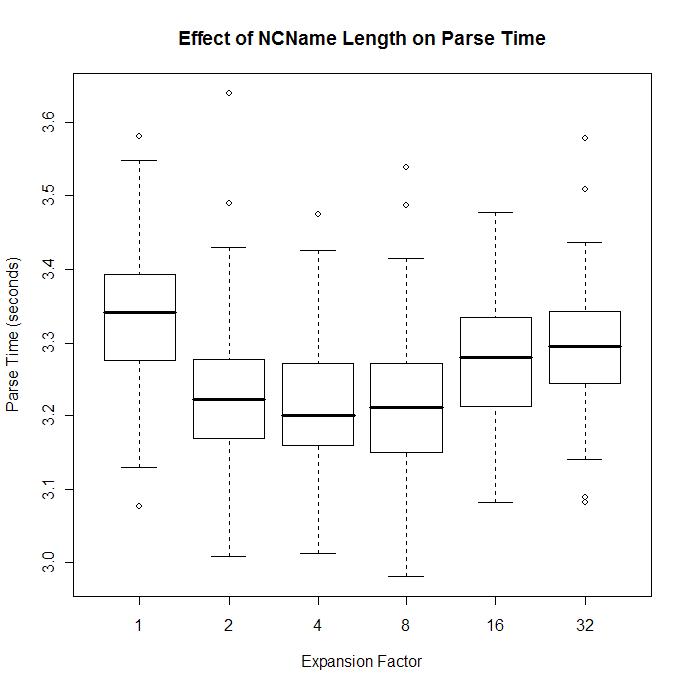 What does this all mean? Even though we expanded some NCNames to 32-times their original length, making a 5x increase in the average NCName length, it made no significant difference in parse time. There is no discernible slow down in parse time as the element and attribute names increase.
What does this all mean? Even though we expanded some NCNames to 32-times their original length, making a 5x increase in the average NCName length, it made no significant difference in parse time. There is no discernible slow down in parse time as the element and attribute names increase.
Keep in mind again that the typical ODF documents shows an average NCName length of 7.7 . The above tests dealt with lengths twice that amount, and still no slowdown.
“Myth Busted”. I revert this topic to the spreaders of such FUD to substantiate their contrary claims.
Interesting. If we turn the table… What could be the reasoning behind using short and obscure tag names in OOXML?
Oh common, nothing busted.
First, it would be fair to link Brian’s post where he discussed the issue of tag length in depth. Here it is.
Now, if you read Brian’s post, he in particular talks about large Excel files, his example has more than 7 million tags. He also says that they see usage of such (and larger) files a lot with their user base. So that is the scenario for which he claims short tag names are important.
And you compare it to a 60 page (large?!?) text document with 51000 tags. Give me a break. That just shows nothing.
Rob, I think you have to look at the impact on working with the compressed package, whether .docx or .odt.
I compared the sizes of the PDFs and the .docx (downloaded as .zip) for the TC45 Final Draft documents. In only one case is the .docx larger than the PDF, and the shrinkage cases are quite startling.
My anecdotal experience (Using OO.o 2.0.2 (the just-appearing release may be better) and Excel 2003 (! with the Microsoft beta plug-in for OOX formats) is odd. Here’s a spreadsheet that I use every day and an odd experience with it:
Excel 2003 binary format, .xls: 144,896 bytes (all numbers as the files were on 2006-10-16 pm)
Excel 2007 beta-OOX format, .xlsx: 64,208 bytes (this is the one I work from just for the experience of it)
OO.o 2.02 Calc ODF format, .ods: 54,041 bytes
The weird thing is that the .xls goes into OO.o pretty quickly, and OO.o saves it as .ods nicely too. But opening the .ods file is painful. More painful than opening the .xlsx in Excel 2003, where it has to go through a not-so-optimized conversion. And way more painful than opening the .xls file in OO.o 2.0.2.
I suspect there are variances all over the map here. Also, there’s no requirement that long QName prefixes be used in ODF (office: could be changed to o: for example), and no requirement that short ones be used in OOX. Namings of the namespace elements are fixed, but we can play with the other bits if it matters.
We will have to watch how implementations are tuned over time to compete with each other for snappy user experience.
orchmid,
I didn’t intentionally republish or change to short descriptions. Must be Thursday, as you say.
The trick in my mind is to design a test that removes the application performance from the equation. Why? Personally, I’m more interested in the XML aspects. Also, Microsoft’s EULA forbids anyone from releasing benchmark numbers on the Office 12 beta without Microsoft’s permission.
As you say, the packaging of the document in the Zip is an important part of the performance, something not measured in this test. However, I have done tests of that before, and did discuss them at the OpenOffice.org conference in Lyon a few weeks ago. The way OOXML packages the XML, into more and smaller XML documents than ODF, actually causes the same document to require more time to parse in OOXML format compared to ODF format. I’ll write up those results in blog form soon. In any case, by looking at just the XML document without the zip archive, I’m better able to target just the impact of the tag name length, which was my object.
Btw, you might want to give OpenOffice.org 2.04 a try. They are claiming significant performance improvements.
davidacoder,
Are you talking about that 130MB monster spreadsheeet? I’m not sure that proves much of anything. The fact that Brian claims to have seen even larger documents is not relevant. It would be futile to compete with Brian on who has seen the largest documents. His experience with OOXML and its 6,000+ specification would win hands down. But I’d note that large documents tend to be broken into smaller documents, for technological as well as organizatioal reasons. Even the OOXML spec ended up being split into 5 parts.
However, I think the important question is what is the size range of typical documents. We need to optimize for those. You want the monster documents not to suffer too much of course, but you want to optimize for the common case.
For Word documents, in one group I looked at (Ecma T45) the most common sized document was 2 pages. The mean length was 34 pages, the median length 8 pages. So picking a 60 page document is certainly a fair example of a medium/medium-large sized document.
[quote]But I’d note that large documents tend to be broken into smaller documents, for technological as well as organizatioal reasons[/quote]
For us one of the only reason to go over to MS Office 2007 is the ability to do large scale Excel spreadsheet. The size of current sheets is really poor which I do not like in Office 2003 and lower.
Large scale spreadsheet require fast performing applications and MS Office is pretty good at it. It might not all be to do with the file optimisation but I think other things might also be important. Like the weird ISO date format ODF uses which is not very good if they actually us it in spreadsheets.
Clearly at the moment Excel is definitly the better option for large spreadsheets. It is fast and has better funtionality. OOo is not on the same level.
However for quite a few companies large scale spreadsheets are less important and so I do not think it should be an important issue. However I do not think it is wise to discuss performance untill OOo manages to squeezes out a lot more performance.
However as I already indicated the long tagging in a standard format is of no real use. Descriptive naming is not needed so it is not really usefull.
“Are you talking about that 130MB monster spreadsheeet?”
Yes. Have you actually read Brian’s post?!? He very clearly states that.
“The fact that Brian claims to have seen even larger documents is not relevant. It would be futile to compete with Brian on who has seen the largest documents”
That is not what I said. Brian claims on his blog that this size of Excel files is not a “fringe case”. From my own experience (economic research) I can only confirm that. We regularily work with Excel files in that size range. This is not about “who has seen the biggest”, but about “is this a very rare case, or something quite common”. At least in the area I am working in it is common and often used. Brian seems to conclude the same from his data.
“So picking a 60 page document is certainly a fair example of a medium/medium-large sized document”
But why on earth have you picked a word document at all?? I assume you are responding to claims from MS that their short tag names are faster. Well, the most detailed claim of that is in Brian’s post to which I linked. And he is ONLY talking about spreadsheets in that one. Now, spreadsheets are not split up into smaller files and files of the size Brian mentions are commonly used. From what you write it seems to be clear that you believe this is a rare case and that therefore a perf hit for those scenarios would be ok for ODF. Fine, but I am sure glad that MS creatd its own file format in that case, because in my daily work I care a great deal about performance of the tools I use. And I would NOT accept a new version of Excel that had significantly worse load times than older version.
My basic point is: MS claimed that long tag names are not good for perf with large spreadsheet files. And you try to bust that “myth” by showing average parsing time for a word document with 60 pages. That just does not make any sense at all.
Chill a little, Davidacoder. My original post was not in response to Brian’s post at all. In fact, I was not aware of it until you mentioned it.
In any case, I’m discussing word processing documents today, not spreadsheets, and no amount of bellyaching from you really changes that fact, does it? You can make all sorts of assumptions about what you think I should be talking about and who I should be responding to, but I assure you that such speculations are a waste of your time, my readers’ time and will not be entertained further.
“I’ve been hearing some rumblings from the north-west that Ecma Office Open XML (OOXML) format has better performance characteristics than OpenDocument Format (ODF), specifically because OOXML uses shorter tag names.”
But you were refering to claims from MS about perf, right? I am sorry, I was under the impression that you meant Brian’s post, but apparently you weren’t.
Can you let us know then what you were refering to? Ideally with a link? Because I just can’t find a claim from MS side anywhere that their file format loads faster for a 60 page word document than ODF. But if you wanted to bust a myth, I assume you do believe they claimed that. Or am I missing something completly here?
I think your best bet is to take the analysis for what it is, a demonstration that the parsing of word processor XML files of medium size are robust under tag size inflations of 32x. The numbers aren’t going to change based on what you think my motivation is.
Also, keep in mind that not every bit of FUD from Microsoft comes on a web page with embedded metadata that says “FUD”. Where it is on the web and I know about it, I link to it, as any regular reader of this blog knows. However, there are other methods for spreading FUD, via personal visits, at conferences, via surrogates or in phone calls.
For well over a year now the whisper message from Microsoft has been generically that “ODF is slow”. I’ve heard it relayed by customers and I’ve heard it told from conference attendees. What I’m showing is that this categorical statement is simplistic and, in the case of word processor files, clearly incorrect.
I’ll deal with spreadsheet files, including the monster ones another time. Python code doesn’t exactly write itself. I’ll even use your document as an example if you think it is typical of the hard-core Excel user. You can get my address under the “Who Am I” link on the main page.
The relative lack of head-to-head performance tests of OpenOffice compared to the Office 2007 beta is simple to understand. Microsoft won’t let anyone talk about performance of their beta products. Take a look at this line from their
End User Licence Agreement (EULA): “7. SCOPE OF LICENSE. …You may not disclose the results of any benchmark tests of the software to any third party without Microsoft’s prior written approval”.
So, evidently, they can go around commenting on OpenOffice performance, but no one else can talk about specific performance scenarios and numbers around Office performance. This is one reason why you’ll see me posting only numbers from application-neutral performance measurements.
That license might not be a real hinderence for independant journalists and consumerorganisations.
However it does seem better to wait for a final release of MS Office 2007.
Hi anonymous,
I’m not a lawyer, so I err on the side of caution. But even aside from the legal issues, I think it is important to look at the pure parse time for a document. A document might be created and saved once in a large desktop editor like Office. But then it will be read many times by other other, smaller tools, search engines, RSS feed generators, etc. The performance of these smaller tools will be more dominated by parse performance.
I have to confirm that I have heard this claim about performance from a couple of different Microsoft sources verbally or in private e-mails. Whether it is a “whisper campaign” or one of these memes that spread without much oversight, I don’t know. I know neither one specified “very large spreadsheets”, which makes sense because my area (which both people know) is in word processing docs. In any case, I think was an excellent analysis.
As the files are all zipped it is also relavant to check the unzip speed as even the most basic of changes probaly needs unzipping.
A big problem is determining speed will be whether the application unzip all of the files. If you leave fileparts unzipped untill later it might be easier to get a fast early reading performance.
Comparing speed will be a very difficult thing no matter what. Certain optimisations like the relationship files in OOXML might very very good for performance in certain tasks but might be slower on regular file editting within the office application. Same for many more differences. I think it is very likely that both parties will be able to show a measuring methode that show their format to their advantage.
Also state of the art XML parsing technology may also help
http://vtd-xml.sf.net