We typically use words to communicate, to be understood. That is the common case, but not the only case. In some situations, words are used like metes and bounds to carefully circumscribe a concept by the use of language, in anticipation of another party attempting a breach. This is familiar in legislative and other legal contexts. Your concept is, “I want to lease my summer home and not get screwed,” and your attorney translates that into 20 pages of detailed conditions. You can be loose with your language, so long as your lawyer is not.
But even among professionals, the attack/defense of language continues. One party writes the tax code, and another party tries to find the loopholes. Iteration of this process leads to more complex tax codes and more complex tax shelters. The extreme verbosity (to a layperson) of legislation, patent claims or insurance policies results from centuries of cumulative knowledge which has taught the drafters of these instruments the importance of writing defensively. The language of your insurance policy is not there for your understanding. Its purpose is to be unassailable.
This “war of the words” has been going on for thousands of years. Plato, teaching in the Akademia grove, defined Man as “a biped, without feathers.” This was answered by the original smart-ass, Diogenes of Sinope, aka Diogenes the Cynic, who showed up shortly after with a plucked chicken, saying, “Here is Plato’s Man.” Plato’s definition was soon updated to include an additional restriction, “with broad, flat nails.” That is how the game is played.
In a similar way Microsoft has handed us all a plucked chicken in the form of OOXML, saying, “Here is your open standard.” We can, like Plato, all have a good laugh at what they gave us, but we should also make sure that we iterate on the definition of “open standard” to preserve the concept and the benefits that we intend. A plucked chicken does not magically become a man simply because it passes a loose definition. We do not need to accept it as such. It is still a plucked chicken.
(This reminds me of the story told of Abraham Lincoln, when asked, “How many legs does a dog have if you call the tail a leg?” Lincoln responded, “Four. Calling a tail a leg does not make it a leg.”)
With the recent announcement here in Massachusetts that the ETRM 4.0 reference architecture will include OOXML as an “open standard” we have another opportunity to look at the loopholes that current definitions allow, and ask ourselves whether these make sense.
The process for recommending a standard in ETRM 4.0 is defined by the following flowchart:
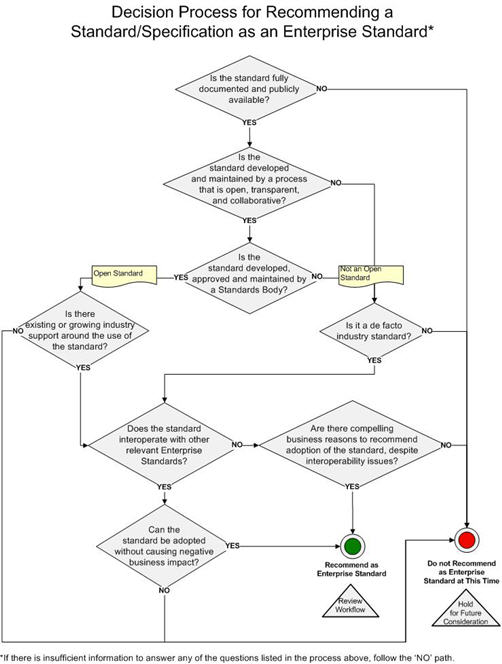
So, let’s go through the first three questions that presumably have already been asked and answered affirmatively in Massachusetts, to see if they conform to the facts as we know them.
- Is the standard fully documented and publicly available? Can we really say that the standard is “fully documented” when the ISO review in the US and in other countries is turning up hundreds of problems that are pointing out that the standard is incomplete, inconsistent and even incorrect? We should not confuse length with information content. Just as a child can be overweight and malrnourished at the same time, a standard can be 6,000 pages long and still not be “fully documented.” Of course, we could just say, “A standard fully documents the provisions that it documents” and leave it at that. But such a tautological interpretation benefits no one in Massachusetts. We should consider the concept of enablement as we do when prosecuting patent applications. If a standard does not define a feature such that a “person having ordinary skill in the art” (PHOSITA) can “make and use” the technology described by the standard without “undue experimentation” then we cannot say that it is “fully documented.” By this definition, OOXML has huge gaps.
- Is the standard developed and maintained in a process that is open, transparent and collaborative? We’re talking about Ecma here. How can their process be called transparent when they do not publicly list the names of their members or attendance at their meetings, do not have public archives of their meeting minutes, their discussion list or document archive, do not make publicly available their own spreadsheet of known flaws in the OOXML specification nor of the public comments they received during their public review period? How is this, by any definition, considered “transparent”? We can also question whether the process was open. When the charter constrains the committee from making changes that would be adverse to a single vendor’s interests, it really doesn’t matter what the composition of the committee is. The committee’s hands are already tied and should not be considered “open.” If I were writing a definition of an open, transparent process, I’d be sure to patch those two loopholes.
- Is the standard developed, approved and maintained by a Standards Body? Without further qualifying “Standards Body” this is a toothless statement. As should be apparent right now, not all SDO’s are created equal. Some of the standards equivalent of diploma mills. Accreditation is the way we usually solve this kind of problem. Ecma’s Class A Liaison status with JTC1 is not an accreditation since their liaison status has no formal requirements other than expressing interesting in the technical agenda of JTC1. In comparison, OASIS needed to satisfy a detailed list of organizational, process, IPR and quality criteria before their acceptence as a PAS Submitter to JTC1/SC34. Why bother having a requirement for a Standards Body unless you have language that ensures that it is not a puppet without quality control?
- Is there existing or growing industry support around the use of the standard? Again, very vague. A look at Google hits for OOXML documents shows that there are very few actually in use. My numbers show that only 1 in 10,000 new office documents are in OOXML format. But I guess that is more than 0 in 10,000 that existing last year. But is this really evidence for “growing industry support”? I’d change the language to require that there be several independent, substantially full implementations.
There are two additional questions which I won’t presume to answer since they rely more on integration with internal ITD processes.
We learn lessons and move on to the next battle. Just as GPLv2 required GPLv3 to patch perceived vulnerabilities, we’ll all have much work to do cleaning up after OOXML. Certainly JTC1 Directives around Fast Tracks will need to be gutted and rewritten. Also, the vague and contradictory ballot rules in JTC1, and the non-existent Ballot Resolution Meeting procedures will need to be addressed. I suggest that ITD take another look at their flowchart as well, and try to figure out how they can avoid getting another plucked chicken in the future.
Overweight & undernourished? Yes, it’s true, but it gave me pause for a minute to figure out because it made me think of someone being thin & fat at the same time.
You might want to make it something like ‘a meal can have too much sugar and too few vitamins at the same time’ or something.
It’s really sad that Microsoft has plunged the whole standards process into Alice in Wonderland contortions. A cut-the-baby-in-half decision like that of Bethann Pepoli (of MA) truly reminds me of the Bush Administration: “No matter what Congress asks, demands, subpoenas, or appropriates, I’m going to do what I want.”
Why bother pretending that she made a decision at all? She had already made up her mind the minute she walked into the job, as we suspected. And don’t fool yourself on hope for changing her mind. If she didn’t consider the facts, technical, legal, or financial, in this decision yesterday, she won’t bother in the future.
This blog would be 10x better if it were a pro-ODF blog rather than an anti-OOXML blog. Even the graphic of your blog says “NO OOXML” rather than anything pro-ODF.
If this blog were 10x better than it is, I wouldn’t have time to respond to insightful comments like yours, would I?
Thanks for writing.
Wat I find very strange is that in the supoedly open standardization proces in OASIS there is a serieus problem.
Gary Edwards as one of the two most active TC members in meetings meetings describes things that happen in the open proces that somehow never made it into the public view. The whole insight in the TC mailing and meeting minutes is a apperantly a hoax as the politics of the parties in those meetings are essentially kept out of the documented information.
Also Gary clearly states that the OASIS TC for OpenDocument is fully under control of Sun and when that was soemhow challenged by another party they were forced out of the TC.
How open, transparant and collaborative is that ??
The guy has a point tho…why so little ODF specific content?
To super spinner – Not all opposition to OOXML is pro ODF. It shouldn’t have to be. OOXML fails on its own merits, and would even if ODF did not exist.
@Anonymous, My contributions on ODF are more technical and are done mainly within the OASIS ODF TC and at conference presentations.
This is my blog, where I have 100% dictatorial authority over subject matter, and the subjects covered will tend to be OOXML and berries. No one forces you to read it. If you don’t like the topic, then change the channel. Also, I tag each post, so you can quickly see which ones are about OOXML versus ODF versus berries.
@Wraith, I think you will find Gary’s notes in the ODF TC mailing list, unedited and uncensored. I think the one case where there were wild accusations of censorship it was found that the person was simply looking at the wrong mailing list archive.
Gary is entitled to his curious ideas, and I’m entitled to disagree with them.
Openness does not fear dissent. Openness does not fear scrutiny. Openness does not fear controversy. Openness does not fear heresy.
http://politics.slashdot.org/comments.pl?sid=259941&cid=20099653
Anyone know how accurate the above is? It’s certainly believable enough, given the other things we’ve seen elsewhere.
Yeah, wraith, if you’re really curious and have time on your hands, look through the archives of either main TC list, or the metadata or formula lists. See if you can discern who seems to be making arguments that ultimately get codified in particular TC decisions.
My argument would be that if you do this, you will find little pattern of the control Gary et al assert. Sometimes Sun people lead the way, but just as often it’s people from KOffice, IBM, or independent people like me.
For example, I had a fairly large role in the recent metadata proposal. At a certain point we were having some fairly heated arguments about some technical details (all public, BTW). It so happened that the positions generally split down between people that worked for Sun and those that did not (including me, and an engineer from IBM). The final proposal (supported by the Sun engineers) in fact reflected a position that they did not at first agree with. That a Sun engineer co-edited the proposal does not take away from the fact that it was a consensus proposal, whose ideas were largely driven by people who don’t work for Sun.
Gary et al (which as far as I can tell means Sam and Marbux; I have nothing to do with this organization anymore) will say this work has been dashed because Sun refused to guarantee preservation of this metadata, but the fact is a) these guys played no constructive role in this discussion (they did not attend the TC call where we discussed this), b) engineers from KOffice and IBM also expressed serious concerns about the implications of this (it was not per se a Sun position), and c) if anything the preservation language is stronger (and certainly not weaker) than that in OOXML.
But to turn all of this around, as Rob said, it’s an interesting irony that an open process (or indeed society) allows for claims of corruption, etc. By contrast, we know nothing about any of the decisions ECMA TC45 made, much less the issues that were raised in that process. We also have no idea about any internal disagreements. That would worry me. Real open standards work almost by definition gets contentious at some point.
You’re dead-on about Ecma not being open or transparent. Not only do they not post their own meetings or minutes, but they never acknowledged any letters I sent them (not even a form letter), nor made any feedback public.
However, you are blowing the enablement issue out of proportion. (True, the compatibility tags have no rightful place in the standard, but they are really a minor issue.) The critique that “person having ordinary skill in the art” could “make and use” OOXML applies equally to ODF. No individual, no matter how talented, can build a modern word processor or spreadsheet from scratch!
Adapting a competing program to use OOXML, however, *should* be within the skill of the developers who maintain those programs. If they could do it for the binary formats, and the XML formats are more or less a transliteration of those binary formats, they can surely do it for the XML formats.
I’ve been hanging out on Microsoft blogs lately, which has given me a good view of one side of the debate. I’ve come here to get a bit from another perspective.
Rob, I think I understand what you’re opposed to in the current process, but I’m not sure what you’d rather be happening. If you could wave a magic wand and make anything you liked happen to OOXML, what would you do? For example, would you make it go away altogether, or make it compatible with ODF, or make it 12,000 pages with sufficient detail on everything mentioned?
– Andrew Sayers
Andrew Sayers, not speaking for Rob or anyone else, for that matter, it’s hard to pinpoint what *CAN* be done with OOXML without substantially changing guardianship and the implementation of OOXML.
The magic wand must be pretty mighty for Microsoft to relinquish control over OOXML to third party that has no partnership ties to Microsoft; remove any reference and/or dependence on prior Microsoft document format implementations; remove dependencies on Microsoft-created document “standards”, such as MathML and VML use existing standards instead, such as SVG.
What I’ve mentioned above are just a few off the top of my head…. So I’d ask, after all those changes, what, exactly, would be the point of OOXML, and how would it be any different than ODF?
The whole point for Microsoft is, that it, as the dominant player in the software industry, is promoting its own document format (over an existing standard, i.e. ODF) as a leverage against competition. Otherwise there is no value for Microsoft to pursue this course of action. So, if you remove everything that is wrong with OOXML (and everything that Microsoft is doing wrong), you’d end up with something that is not even worth mentioning when compared to ODF.
Lucas,
I realise the magic wand question is rather implausible, but I find it difficult to really understand Rob’s approach without knowing what exactly he’s advocating. For example, posts on this blog tend to widen the (already large) gulf between the ODF and OOXML communities, because there’s a constant undertone that we should judge Microsoft for OOXML’s failings, rather than be a critical friend. That’s entirely appropriate if Rob’s opinion is that OOXML should cease to exist, but counter-productive if he wants ODF and OOXML to some day become compatible.
The point of this sort of hypothetical is to shake loose people’s underlying beliefs, and your answer tells me that you don’t think OOXML addresses any problems that ODF doesn’t. I mentioned before that there’s a gulf between the ODF and OOXML communities, and one of the effects of that is that each side only really gets to see a cartoonish sketch of the other side’s position. Microsoft do have valid arguments about why ODF isn’t sufficient, and I’ll give you a couple if you’ll promise not to claim I agree with them just because I understand them:
1) “High fidelity” (i.e. bug-for-bug) compatibility with old versions of Office. Although it’s rightly pointed out that nobody has any serious expectation for two versions of Word to display a complex document exactly the same, people do expect different versions of Excel to return the same value for any given input to a function, no matter how many bugs their spreadsheet relies on. Microsoft’s solutions (e.g. the whole issue with dates) aren’t great, but nobody’s going to move their documents over to ODF if they have so much as a whiff of fear that doing so will silently break a spreadsheet that their business depends on.
2) Being fast, rather than beautiful. Speed isn’t an issue for sensible uses of documents, but when people start making things like 60,000 row spreadsheets, there is an argument that the elegance of ODF leads to unacceptable slowness. And yes, people should use a database instead. They should also eat healthy food and get regular exercise, but saying it doesn’t make it so.
I don’t necessarily agree with these arguments, but dismissing them as flimsy excuses will only sway people that agree with you already.
– Andrew
Hi Andrew,
I’ll answer your question fully in an upcoming blog post. It is a good question and deserves a good answer.
To your specific points, I did a study of OOXML versus ODF performance a while ago, and found that, in the word processor format at least, OOXML is much slower than ODF.
Also, the claims of fidelity with legacy documents is more a statement of what MS Office does. It really is not a property of the OOXML format, which has almost no details regarding compatibility. In fact, many of the comments registered in the US are about compatibility settings in OOXML that lack details. Think of it this way — even if Microsoft never published the OOXML specification, their Office product would have backwards compatibility. So the compatibility is not dependent on the format. Only to the extent that this compatibility is fully and accurately detailed in a publicly available document, with IP rights, etc., is this something that others can practice as well. So criticisms of whether in fact OOXML is sufficient to this purpose are of great importance.
Rob,
I await your post keenly, and I’ll leave my main comments until then, but I’d just like to make one point:
There seems to be a big gap between the problems that OOXML addresses and those that it solves to everybody’s satisfaction, so it’s important that we’re clear about which we’re discussing at any one time. Your articles make good points about OOXML’s speed and lack of detail, and the articles help answer the question of whether OOXML has yet met its design goals, but they only hint at the nature of those goals.
If bug-for-bug compatibility is important for example, the next question is whether it’s compatible with ODF: if so, the logical course of action is to fold compatibility in; if not, the logical course of action is a second standard. Only after that does the question of OOXML’s fitness for purpose comes in.
– Andrew
Andrew,
I don’t see a need for compatibility settings inside a new format at all. It should be the responsibility of the converting program to handle any “bugs” and put them into the new standard sanely. The whole compatibility argument just seems like misdirection.
As an example, there shouldn’t be a “autoSpaceLikeWord95” property in a new format. If there are special spacing rules for that version, the program should be able to convert them to something in the new format.
For items like language lists, instead of keeping the fixed list, simply add the logic to map these things in the application.
For things like mathematical formulas or date math, adding things to a new format like a flag to the formula to indicate “broken” calculation would be sane instead of codifying incorrect behavior, avoiding the purpose of getting it right.
When you have a chance to do something correctly and use existing standards, you should. It would also very likely reduce complexity of implementation.
If OOXML was to clean up those types of things, it would be a lot closer to harmonization with ODF, which should be the ultimate goal.
Youngmug,
There’s a lot to be said for your approach, although the arguments involved are sadly more complicated than you make out.
But first, carrying on my theme of being a stickler for details, would it be fair to say that you’re not opposed to adding features if it’s the only way of achieving compatibility, so long as the features expose functionality that can be used on its own merits?
For example, if “autospaceLikeWord95” turns out to mean “calculate spacing using function F on even numbered pages, but function G on odd numbered pages”, you would recommend adding something like “autospaceEvenPagesFunction” and “autospaceOddPagesFunction”?
(I’m not making any particular point here, just making sure we’re on the same page).
With that out of the way, I’ll begin my post proper. In fact, I’ve got way more to say than can reasonably fit into a single comment, so I’ll limit myself to one philosophical and one practical issue. Philosophy first:
One thing you have to remember when looking at Microsoft is that they’ve been doing their own thing behind closed doors for the past 20 -30 years, and although they seem to have argued out all the same big debates that were going on in the rest of the computing world in the 80’s and 90’s, they’ve come to very different conclusions on many of them. Understanding what they say and do often means rethinking some of the fundamental stuff we’ve all taken for granted for the past few decades.
Going back to an example from an earlier post of mine, the public computing community generally agreed that a good file format specification should describe an idealised view of the data it’s representing. This leads to file formats that are portable and easy for beginners to learn, potentially at the cost of implementation speed or simplicity (because you need to load a larger document and translate it into internal data structures).
When the same argument was had inside Microsoft, my guess is that they concluded “our customers don’t care about any of that stuff, they want fast programs, and they want us to add features instant they request them”. As such, Microsoft seems to have decided that a good format should be an accurate representation of the data in memory at the moment the user presses ‘save’. This leads to file formats that are bound very tightly to the application they’re developed on, but which are therefore fast (loading a file involves very little processing), and easy to change (adding a feature means adding a data structure that doubles as the file format representation).
Now that Microsoft have decided to open up their formats, we have to merge these two ideologies back together again, which means reopening arguments we thought were settled for good. As well as acknowledging that each side has a valid, philosophically different point of view, it’s important to recognise a bit of psychology: as you read the above paragraphs, you were probably thinking “so Microsoft want me to give up compatibility for a bit of speed? That’s just not going to happen”; similarly, Microsofties would read the above and think “so they want to tie up the simplest of features in red tape so that some newbie can write a homebrew word processor? That’s just not going to happen”. Arguments like Rob’s about the actual, measured speed of different formats are important because they address they address the legitimate advantages that Microsoft are afraid of losing.
Moving on to the practical issue, you said that date maths should use a “broken” tag to indicate that the file depends on broken handling of dates – I’ll pick on that because it’s a topic I know a bit about, and is probably a good example of the more general issues. Personally, I still have hope that some solution can be found that properly deprecates brokenness, but I’m not convinced about your solution. How would programs handle such a flag for example? If they were to pop up a message saying “your program might have a date bug” each time the file is opened, users would ignore the popup then get upset when their spreadsheets broke without giving any further warning.
Also, I suspect you’re underestimating just how nasty Excel’s file format is. For example, any fully backwards-compatible program needs a strategy to deal with formulae up to and including this level of evilness:
=IMREAL(IMEXP(COMPLEX(0, “03/01/1900 03:23:53.606”))) + WEEKDAY(“4 March 1900”)=0
As I said at the start, there’s a lot to be said for your approach, it’s just that you need to be looking much deeper if you want to have a productive debate with Microsoft.
– Andrew
Andrew, thanks for the detailed comment. It certainly was very interesting.
Correct, I am not opposed to adding features if those features are required to preserve layout, but can also be used on their own merits. If, instead of telling a program to “act like Word would” you can instead describe the actual details of how to actually display it, that would be a great thing.
I can see and unerstand MS’ philosophy. It certainly is a tricky question. Obviously, some documents require a longer life and for others it doesn’t matter so much. With modern computers being so fast, however, the difference in speed between a well-structured portable format and a tightly bound format is likely not nearly so big as it used to be. We’ve come a long way since 33mHz processors and low memory, and that certainly would affect the debate. As for complexity, well, that is to be determined. With the burden on the format to carry legacy information (instead of translating such), OOXML could be considered more complex to implement at this point in time.
The practical issues in dealing with fixing things like formulas will certainly take some time to figure out. Luckily there are many smart people working on ODF formulas, and they are likely considering this issue. It would be a shame to see broken math codified in either format.
Youngmug,
On the topic of adding features, I think we can agree that it’s always better to add a feature that is designed to add functionality, even if the reason for its existence is purely compatibility. In my opinion, features with such a narrow scope are inelegant, and inelegant solutions usually lead to trouble sooner or later. Sadly, this subtle argument seems to have been drowned out by arguments about how the specific instances of compatibility features in Office Open XML are poorly documented.
I also agree that loading speed is an odd argument. Moore’s Law (and its relatives) suggests that if a file takes N seconds to load today, it’ll take N/2 seconds in August 2009 and N/32 seconds by August 2017.
Then again, my opinions are often wrong, so now I’ve got two more questions I want to ask Brian Jones (Microsoft’s most technical OOXML blogger). I plan to bring them up next time the conversation moves around to either of these topics, so you might want to keep an eye out there.
I could well be wrong about this, but my understanding is that OpenDocument 1.2 is nearing completion, and will contain the results of the formula committee’s work. That will hopefully move the discussion forward about how to resolve the issues around formulae.
Anyway, I’m really just replying because I’m so glad to see that I’m not the only person in the world that’s still making his mind up about all of this!
– Andrew