Last year, when I was socializing the idea of creating the OASIS ODF Interoperability and Conformance TC, I gave a presentation I called “ODF Interoperability: The Price of Success”. The observation was that standards that fail never need to deal with interoperability. The creation of test suites, convening of multi-vendor interoperability workshops and plugfests is a sign of a successful standard, one which is implemented by many vendors, one which is adopted by many users, one which has vendor-neutral venues for testing implementations and iteratively refining the standard itself.
Failed standards don’t need to work on interoperability because failed standards are not implemented. Look around you. Where are the OOXML test suites? Where are the OOXML plugfests? Indeed, where are the OOXML implementations and adoptions? Microsoft Office has not implemented ISO/IEC 29500 “Office Open XML”, and neither has anyone else. In one of the great ironies, Microsoft’s escapades in ISO have left them clutching a handful of dust, while they scramble now to implement ODF correctly. This is reminiscent of their expensive and failed gamble on HD DVD on the XBox, followed eventually by a quick adoption of Blue-ray once it was clear which direction the market was going. That’s the way standards wars typically end in markets with strong network effects. They tend to end very quickly, with a single standard winning. Of course, the user wins in that situation as well. This isn’t Highlander. This is economic reality. This is how the world works.
Although this may appear messy to an outside observer, our current conversation on ODF interoperability is a good thing, and further proof, to use the words Microsoft’s National Technology Director, Stuart McKee, that “ODF has clearly won“.
Fixing interoperability defects is the price of success, and we’re paying that price now. The rewards will be well worth the cost.
We’ve come very far in only a few years. First we had to fight for even the idea and acceptance of open standards, in a world dominated by a RAND view of exclusionary standards created in smoke filled rooms, where vendors bargained about how many patents they could load up a standard with. We won that battle. Then we had to fight for ODF, a particular open standard, against a monopolist clinging to its vendor lock-in and control over the world’s documents. We won that battle. But our work doesn’t end here. We need to continue the fight, to ensure that users of document editors, you and I, get the full interoperability benefits of ODF. Other standards, like HTML, CSS, EcmaScript, etc., all went through this phase. Now it is our turn.
With an open standard, like ODF, I own my document. I choose what application I use to author that document. But when I send that document to you, or post it on my web site, I do so knowing that you have the same right to choose as I had, and you may choose to use a different application and a different platform than I used. That is the power of ODF.
Of course, the standard itself, the ink on the pages, does not accomplish this by itself. A standard is not a holy relic. I cannot take the ODF standard and touch it to your forehead say “Be thou now interoperable!” and have it happen. If a vendor wants to achieve interoperability, they need to read (and interpret) the standard with an eye to interoperability. They need to engage in testing with other implementations. And they need to talk to their users about their interoperability expectations. This is not just engineering. Interoperability is a way of doing business. If you are trying to achieve interoperability by locking yourself in a room with a standard, then you’ll have as much luck as trying to procreate while locked in a room with a book on human reproduction. Interoperability, like sex, is a social activity. If you’re doing it alone then you’re doing it wrong.
Standards are written documents — text — and as such they require interpretation. There are many schools of textual interpretation: legal, literary, historic, linguistic, etc. The most relevant one, from the perspective of a standard, is what is called “purposive” or “commercial” interpretation, commonly applied by judges to contracts. When interpreting a document using an purposive view, you look at the purpose, or intent, of a document in its full context, and interpret the text harmoniously with that intent. Since the purpose of a standard is to foster interoperability, any interpretation of the text of a standard which is used to argue in favor of, or in defense of, a non-interoperable implementation, has missed the mark. Not all interpretations are equal. Interpretations which are incongruous with the intent of standardization can easily be rejected.
Standards can not force a vendor to be interoperable. If a vendor wishes deliberately to withhold interoperability from the market, then they will always be able to do so, and, in most cases, devise an excuse using the text of the standard as a scapegoat.
Let’s work through a quick example, to show how this can happen.
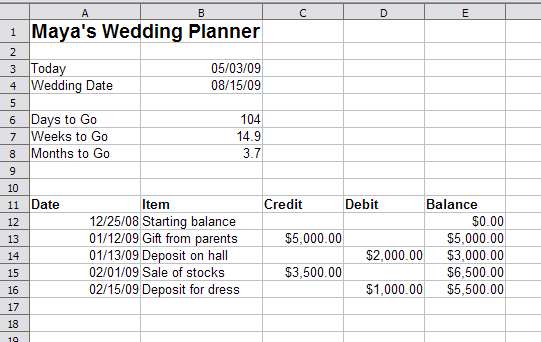
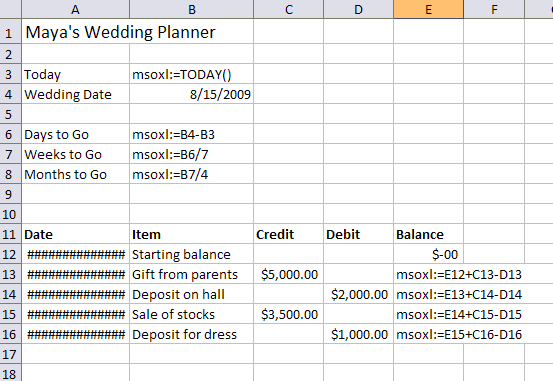
OpenFormula is the part of ODF 1.2 that defines spreadsheet formulas. The current draft defines the addition operator as:
6.3.1 Infix Operator “+”
Summary: Add two numbers.
Syntax: Number Left + Number Right
Returns: Number
Constraints: None
Semantics: Adds numbers together.
I think most vendors would manage to make an interoperable implementation of this. But if you wanted to be incompatible, there are certainly ways to do so. For example, given the expression “1+1” I could return “42” and still claim to be interoperable. Why? Because the text says “adds numbers together”, but doesn’t explicitly say which numbers to add together. If you decided to add 1 and 41 together, you could claim to be conformant. OK, so let’s correct the text so it now reads:
6.3.1 Infix Operator “+”
Summary: Add two numbers.
Syntax: Number Left + Number Right
Returns: Number
Constraints: None
Semantics: Adds Left to Right.
So, this is bullet-proof now, right? Not really. If I want to, I can say that 1+1 =10, if I want to claim that my implementation works in base 2. We can fix that in the standard, giving us:
6.3.1 Infix Operator “+”
Summary: Add two numbers.
Syntax: Number Left + Number Right, both in base 10 representations
Returns: Number, in base 10
Constraints: None
Semantics: Adds Left to Right.
Better, perhaps. But if I want I can still break compatibility. For example, I could say 1+1=0, and claim that my implementation rounds off to the nearest multiple of 5. Or I could say that 1+1 = 1, claiming that the ‘+’ sign was taken as representing the logical disjunction operator rather than arithmetic addition. Or I could do addition modulo 7, and say that the text did not explicitly forbid that. Or I could return the correct answer some times, but not other times, claiming that the standard did not say “always”. Or I could just insert a sleep(5000) statement in my code, and pause 5 seconds every time the an addition operation is performed, making a useless, but conformant implementation And so on, and so on.
The old adage holds, “It is impossible to make anything fool- proof because fools are so ingenious.” A standard cannot compel interoperability from those who want resist it. A standard is merely one tool, which when combined with others, like test suites and plugfests, facilitates groups of cooperating parties to achieve interoperability.
Now is the time to achieve interoperability among ODF implementations. We’re beyond kind words and empty promises. When Microsoft first announced, last May, that it would add ODF support to Office 2007 SP2, they did so with many fine words:
- “Microsoft Corp. is offering customers greater choice and more flexibility among document formats”
- Microsoft is “committed to work with others toward robust, consistent and interoperable implementations”
- Chris Capossela, senior vice president for the Microsoft Business Division: “We are committed to providing Office users with greater choice among document formats and enhanced interoperability between those formats and the applications that implement them”
- “Microsoft recognizes that customers care most about real-world interoperability in the marketplace, so the company is committed to continuing to engage the IT community to achieve that goal when it comes to document format standards”
- Microsoft will “work with the Interoperability Executive Customer Council and other customers to identify the areas where document format interoperability matters most, and then collaborate with other vendors to achieve interoperability between their implementations of the formats that customers are using today. This work will continue to be carried out in the Interop Vendor Alliance, the Document Interoperability Initiative, and a range of other interoperability labs and collaborative venues.”
- “This work on document formats is only one aspect of how Microsoft is delivering choice, interoperability and innovative solutions to the marketplace.”
So the words are there, certainly. But what was delivered fell far, far short of what they promised. Excel 2007 SP2 strips out spreadsheet formulas when it reads ODF spreadsheets from every other vendor’s spreadsheets, and even from spreadsheets created by Microsoft’s own ODF Add-in for Excel. No other vendor does this. Spreadsheet formulas are the very essence of a spreadsheet. To fail to achieve this level of interoperability calls into question the value and relevance of what was touted as an impressive array of interoperability initiatives. What value is an Interoperability Executive Council, an Interop Vendor Alliance, a Document Interoperability Initiative, etc., if they were not able to motivate the most simple act: taking spreadsheet formula translation code that Microsoft already has (from the ODF Add-in for Office) and using it in SP2?
The pretty words have been shown to be hollow words. Microsoft has not enabled choice. Their implementation is not robust. They have, in effect, taken your ODF document, written by you by your choice in an interoperable format, with demonstrated interoperability among several implementations, and corrupted it, without your knowledge or consent.
There are no shortage of excuses from Redmond. If customers wanted excuses more than interoperability they would be quite pleased by Microsoft’s prolix effusions on this topic. The volume of text used to excuse their interoperability failure, exceeds, by an order of magnitude, the amount of code that would be required to fix the problem. The latest excuse is the paternalistic concern expressed by Doug Mahugh, saying that they are corrupting spreadsheets in order to protect the user. Using a contrived example, of a customer who tries to add cells containing text to those containing numbers, Doug observes that OpenOffice and Excel give different answers to the formula = 1+ “2”. Because all implementations do not give the same answer, Microsoft strips out formulas. Better to be the broken clock that reads the correct time twice a day, than to be unpredictable, or as Doug puts it:
If I move my spreadsheet from one application to another, and then discover I can’t recalculate it any longer, that is certainly disappointing. But the behavior is predictable: nothing recalculates, and no erroneous results are created.
But what if I move my spreadsheet and everything looks fine at first, and I can recalculate my totals, but only much later do I discover that the results are completely different than the results I got in the first application?
That will most definitely not be a predictable experience. And in actual fact, the unpredictable consequences of that sort of variation in spreadsheet behavior can be very consequential for some users. Our customers expect and require accurate, predictable results, and so do we. That’s why we put so much time, money and effort into working through these difficult issues.
This bears a close resemblance to what is sometimes called “Ben Tre Logic”, after the Vietnamese town whose demise was excused by a U.S. General with the argument, “It became necessary to destroy the village in order to save it.”
Doug’s argument may sound plausible at first glance. There is that scary “unpredictable consequences”. We can’t have any of that, can we? Civilization would fall, right? But what if I told you that the same error with the same spreadsheet formula occurs when you exchange spreadsheets in OOXML format between Excel and OpenOffice? Ditto for exchanging them in the binary XLS format. In reality, this difference in behavior has nothing to do with the format, ODF or OOXML or XLS. It is a property of the application. So, why is Microsoft not stripping out formulas when reading OOXML spreadsheet files? After all, they have exactly the same bug that Doug uses as the centerpiece of his argument for why formulas are stripped from ODF documents. Why is Microsoft not concerned with “unpredictable consequences” when using OOXML? Why do users seem not to require “accurate, predictable results” when using OOXML? Or to be blunt, why is Microsoft discriminating against their own paying customers who have chosen to use ODF rather than OOXML? How is this reconciled with Microsoft’s claim that they are delivering “choice, interoperability and innovative solutions to the marketplace”?