It came to me after listening to the State of the Union Address: Can we tell whether a speech was from a Democrat or a Republican President, purely based on metrics related to the words used? It makes sense that we could. After all, we can analyze emails and detect spam that way. Automatic text classification is a well known problem. On the other hand, presidential speeches go back quite a bit. Is there a commonality of speeches of, a Democrat in 2014 with one from 1950? Only one way to find out…
I decided to limit myself to State of the Union (SOTU) addresses, since they are readily available, and only those post WW II. There has been a significant shift in American politics since WW II so it made sense, for continuity, to look at Truman and later. If I had included all of Roosevelt’s twelve (!) SOTU speeches it might have distorted the results, giving undue weight to individual stylistic factors. So I grabbed the 71 post WWII addresses and stuck them into a directory. I included only the annual addresses, not any exceptional ones, like G.W. Bush’s special SOTU in September 2001.
I then used R’s text mining package, tm, to load the files into a corpus, tokenize, remove punctuation, stop words, etc. I then created a document-term matrix and removed any terms that occurred in fewer than half of the speeches. This left me with counts of 610 terms in 71 documents.
Then came the fun part. I decided to use Pointwise Mutual Information (PMI), an information-centric measure of association from information retrieval, to look at the association between terms in the speeches and party affiliation. PMI shows the degree of association (or “co-location”) of two terms while also accounting for their prevalence of the terms individually. Wikipedia gives the formula, which is pretty much what you would expect. Calculate the log probability of the co-location and subtract out the log probability of the background rate of the term. But instead of looking at the co-occurrence of two terms, I tried looking at the co-occurrence of terms with the party affiliation. For example, the PMI of “taxes” with the class Democrat would be: log p(“taxes”|Democrat) – log p(“taxes”). You can see my full script for the gory details.
Here’s what I got, listing the 25 highest PMI terms for Democrats and Republicans:


So what does this all mean? First note the difference in scale. The top Republican terms had higher PMI than the top Democrat terms. In some sense it is a political Rorschach test. You’ll see what you want to see. But in fairness to both parties I think this does accurately reflect their traditional priorities.
From the analytic standpoint the interesting thing I notice is how this compares to other approaches, like using classification trees. For example, if I train the original data with a recursive partitioning classification tree, using rpart, I can classify the speeches with 86% accuracy by looking at the occurrences of only two terms:
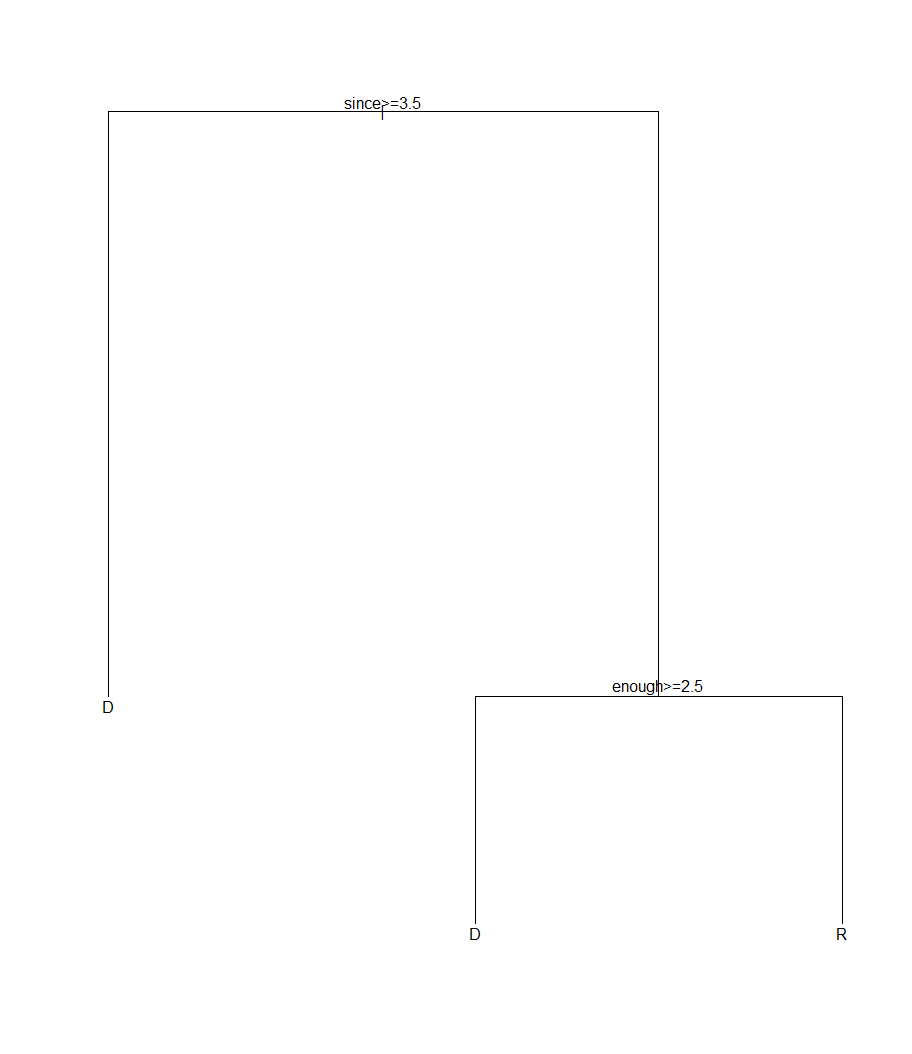
Not a lot of insight there. It essentially latched on to background noise and two semantically useless words. So I prefer the PMI-based results since they appear to have more semantic weight.
Next steps: I’d like to apply this approach back to speeches from 1860 through 1945.
Leave a Reply